Cornell Mars Rover



I’ve been a member of the team since my first year at Cornell and was the Software Subteam lead for the 22-23 school year. For my senior year, I’ve decided to take a bit of a backseat role to make sure I have time for other things I want to do this year such as research.
We compete every year in the University Rover Challenge, held in Utah.
During my time on the team, I:
- Led a team of 12 to iteratively develop software for a rover using ROS (Robot Operating System), C++, and Python
- Redesigned the codebase to focus on code quality, maintainability, documentation, testing, readability, and reliability
- Created a runtime fault handling and dependency management system, and wrote a 300+ page Modern C++ reference guide
- Improved the pathfinding algorithm to support the autonomous location of AR tags and traversal through goalposts
- Implemented a multithreaded hardware abstraction layer and a communication format to support greater message throughput to the microcontroller. This improved performance by over 400%, reduced code coupling, and drastically increased testability
ASCII HW Message Format (First Year)
The first thing I worked on was implementing the CS side of a new message format that transmitted messages to the microcontroller managed by the electrical subteam. The previous year, the team decided to switch from a binary to an ASCII representation for easier debugging.
Concurrent Hardware Abstraction Layer (First Year)
After the message format, I was tasked with improving message throughput so that our HW abstraction layer could handle the number of messages sent by the inverse kinematics controller for the arm, which was new the previous year.
To do this, my first thought was to use asynchronous programming (in fact, the project was dubbed Async HAL), however, this would require changing a lot of the code that interfaced with HAL which was written with sequential communication in mind. Since we used ROS, each module in our software was run in separate processes (known as nodes), which communicate over two-way channels known as actions. Therefore, what I ended up doing was multithreading the action server with a thread pool that handles action requests on the HAL side so that many clients can send requests at once. So for each request, the action server would push the request onto a thread pool to be processed in parallel with other requests.
Of course, we still only had one port going to the actual HW. To work around this, I designed a new port interface for reading and writing data and a port decorator which made accessing a decorated port thread-safe. This was achieved by having all calls to write to the port copy the message into a shared buffer and having a single thread handle sending the buffered messages to the HW. Reading was done similarly but in reverse with a single thread reading the port and distributing the messages to the correct client threads by matching message IDs of the SW requests and HW responses.
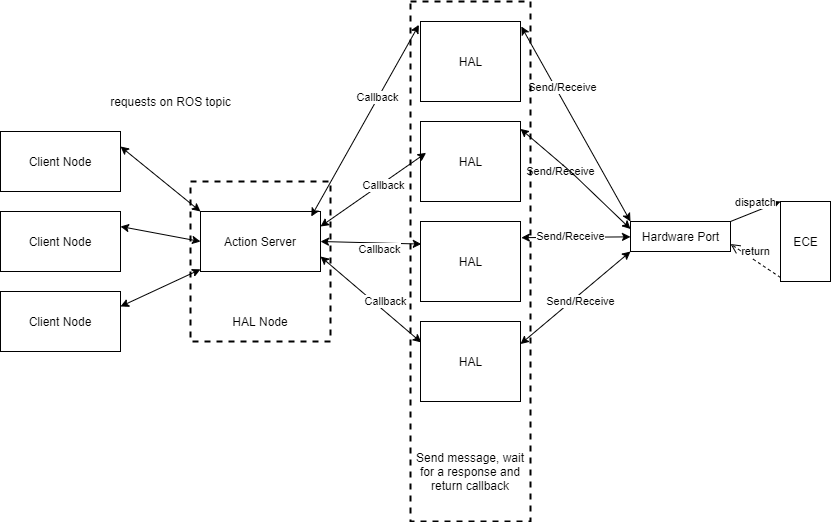
The new port interface also allowed SW testing. All we had to do was create a port that would read and write a memory buffer, and the complex logic of the decorator could be tested by decorating the memory port.
Things did not go smoothly though. I stumbled through bugs caused by race
conditions for over three months where I was a slave to the green PASSED
and red FAILED messages of my unit tests. I don’t remember what eventually fixed it,
but I think it had something to do with calling a function
that, unbeknownst to me, yielded control back to ROS.
Autonomy Refactor (Second Year)
During my sophomore year, I updated our autonomy algorithm to support passing through goalposts instead of just arriving near an AR tag. While doing this, I also refactored and completely reimplemented the algorithm using the State design pattern.
We use ROS to handle the obstacle avoidance and navigation to GPS coordinates, but it is up to us to implement the logic so that our rover can search for AR tags and navigate through goals.
Our algorithm revolves around a simple, yet very clever and effective idea that I won’t disclose.
I have some design documents and presentations I wrote describing this in more detail, but cannot share them here.
Fault Handling (Third Year)
As the subteam lead, I didn’t do a whole lot of implementation work during my third year. However, one thing I did do was create a decentralized fault-handling system.
The core idea is that we have a dependency graph of nodes. We never want a node to be running when something it depends on is not running, and we’d like no nodes whose sole purpose was to serve another node to be running when the system they exist to support is not alive.
To achieve this goal, when a node starts up, it activates its chain of dependencies in topological order and waits until all dependencies are running before continuing. On error, the node would do a similar process, notifying all nodes it supports that they must shut down and all nodes that support it that a depender is shutting down. After a few seconds, a fault handler would attempt to restart all of the shutdown nodes in topological order.
Subteam Lead (Third Year)
My main role was working with the other subteams on integration, assigning tasks, providing guidance, and other miscellaneous work.
This year, we were migrating from ROS 1 to ROS 2 which entailed reimplementing everything. We focused a lot more on using ROS libraries to avoid the extra work.
At the beginning of the year, I set up a lot of DevOps stuff:
- Doxygen-generated code docs
- Switched over to Clang, Clang-tidy, Clang-format
- Created formatting rules loosely based on Google’s style guide
- Established linting rules and a coding standard
- Created a Python unit testing library on top of Pytest
- Setup a CI and nightlies with Github Actions
I also introduced a new Agile-ish development model that focused on iterative development instead of the old, design-implement-test workflow that would delay testing until the spring. We used 3-4 week-long sprints, where I would help break up everybody’s projects into tasks that can be accomplished in a few weeks. I found it helpful to scope some tasks ahead of time in order to be able to provide resources and some insight into a direction to attack the problem. These changes, along with a greater focus on early SW testing in the simulation were well-received by the team.
We met for three, 2-hour work sessions a week along with independent work. While I was initially opposed to that much “oversight”, we found the designated work times to be really helpful to avoid getting too busy with other classes, and a set period where I am available to answer questions in person also proved useful.