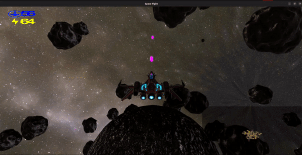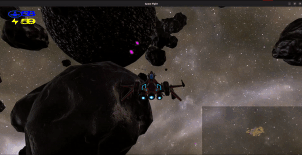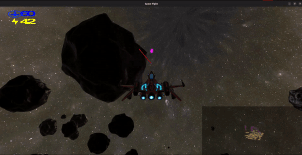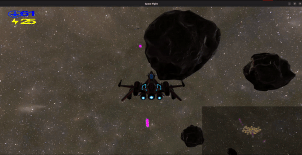
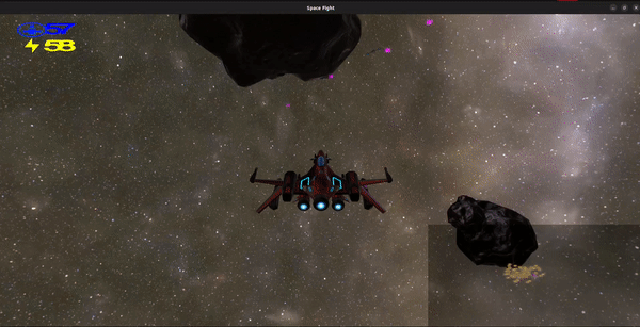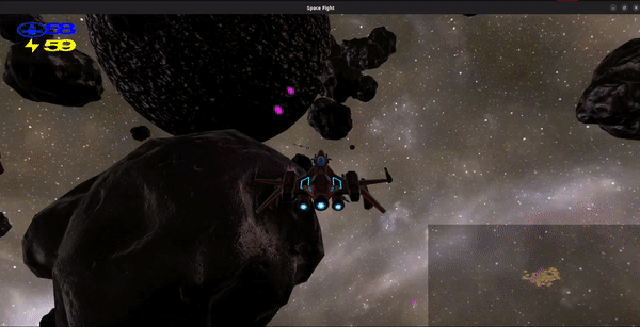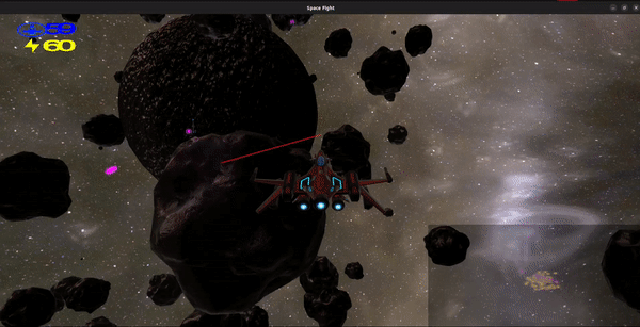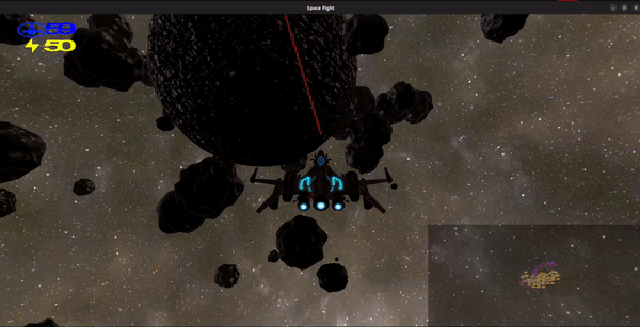
Project Oort
is a third-person space shooter game implemented in over 20k+ lines of Rust with
OpenGL. You control a starfighter that must battle AI enemies in a
zero-gravity asteroid field while managing the ship’s energy and shield.
Your ship is armed with a photon cannon, cloaking, and a gravity tether that
allows you to swing from or pull asteroids or other ships.
There’s no deep aim of the game, the goal is to shoot down your enemies without
getting shot down yourself. Note that, there is no atmosphere and
therefore there is no drag that will slow down your ship.
The ship moves at constant velocity unless accelerated or decelerated.
Controls: Left click to fire. Right-click to fire a grappling shot.
T to turn invisible. W, S to accelerate forwards or backward,
and mouse movement to control the rotation of the ship.
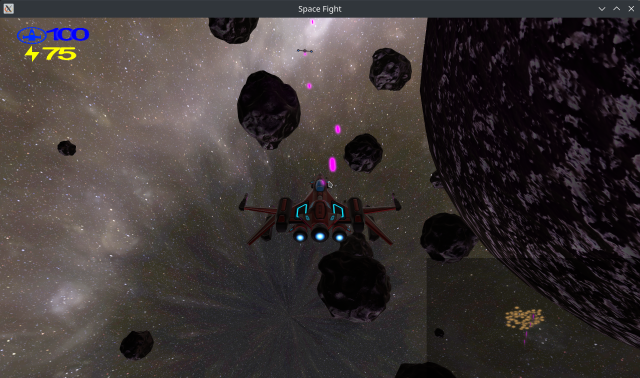
Shield: You have a shield, denoted by the blue number at the top left.
If this goes to 0, your ship is destroyed and you will respawn somewhere
randomly on the map. Your shield will regenerate slowly over time.
Energy: Denoted by the yellow number in the top left, your energy is
necessary to fire lasers and accelerate your ship.
Your energy will regenerate slowly over time.
Minimap: In the bottom right, you have a minimap to see where you are
relative to lasers and asteroids. The minimap is a 2D projection
of 3D space which is “top-down” respective to your camera angle.
Grappling Hook: You can fire a “hook shot” by pressing and holding right-click.
Once landed on an object, a tether will be formed between the target object and the shooter.
The distance between the shooter and the object will not exceed the distance
between them when the tether was first formed. The amount a tethered object moves to ensure
this depends on the momentum of each tethered object.
To release the tether, release right-click.
Technical Implementations:
- A Forward+ physically based rendering engine that supports
area lights, cascading shadow maps, soft shadows, animated models, and
ray-marched volumetrics
- A 3-phase collision detection system utilizing an Octree, Bounding Volume
Hierarchy of Oriented Bounded Boxes, and triangle intersections parallelized
with compute shaders. You can read more about this here.
- A behavior tree AI and a modification of A* for pathfinding
- Rigid Body Simulation with rotational motion
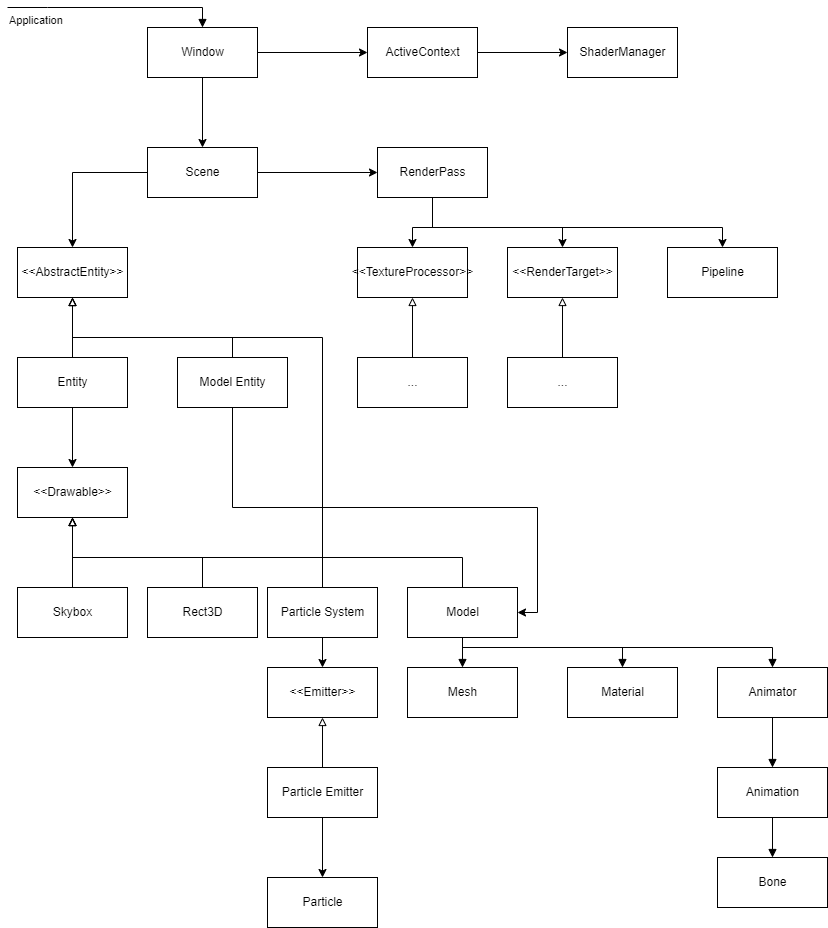
The graphics engine was designed, from the ground up using OpenGL.
The general structure is built on a pipeline system of RenderPasses,
RenderTargets and TextureProcessors. A RenderTarget is, well,
a render target where objects are drawn to and (typically) produces a texture.
A TextureProcessor is essentially a function on textures that takes input textures
and may produce an output texture. To pass extra state between stages, each stage has
read/write access to a pipeline cache.
A RenderPass, strings together multiple RenderTargets and TextureProcessors,
ordering them at the discretion of the Pipeline, which holds
a dependency graph of the stages in the RenderPass. The Pipeline is defined
by the user via a custom Rust DSL.
A Scene has a list of Entitys and RenderPasses. Each Entity can define
general properties that a RenderPass can access to render the Entity properly,
such as its required render order. A final Compositor can compose the results
of multiple RenderPasses together.
I have a blog post about how my graphics engine handles transparent objects
here. Below is a diagram of the relevant architecture:
I have a very detailed blog post about this here.
A rigid body simulation is used to handle the physics and collision resolution.
Each rigid body is given a manually assigned mass
or a manually assigned density.
In the latter case, we can compute an estimated mass using the volume of the
body’s bounding box. For each rigid body, we estimate an inertial tensor
based on the vertices of the Rigid Body’s collision mesh.
Then at each step of the simulation, we determine the magnitude, direction,
and point of application of the forces that are applied to each object.
We then use the impulse-momentum theorem to compute changes in velocity.
We subtract the point of application from the object’s center of
mass to estimate a lever arm and compute an applied torque for the object.
Using this and the inertial tensor, we compute a rotational angular velocity.
I chose not to handle rotational velocity updates quite the same for
the user-controlled ships for now,
because it made the controls upon colliding with something feel unintuitive
(ie. you lost control as the collision would impart a torque, rotating
your ship).
For collision resolution, we compute a point of contact by
averaging the centroids of colliding triangles and an impact force
based on the momentum of colliding bodies.
The basic premise of the grappling hook is that if the two objects connected
by the “cable” are too far apart, we essentially update the velocities of
both objects by treating the cable being pulled as an elastic collision.
For the AI, a behavior tree is used to control the non-player enemy in the game.
The behavior tree is built up of Sequence, Fallback, and ParallelSequence
control nodes and custom action nodes for moving and firing.
Pathfinding is done using a 3D implementation of A*,
by tiling the 3D space into little cubes.
Once a path has been computed, a simple local navigator just
follows the path in segments of straight lines.
Source